 HDFS(Hadoop Distributed File System)作为Hadoop下的一个子项目,是目前使用极为广泛的分布式文件系统。它的设计目的是提供一个高容错,且能部署在廉价硬件的分布式系统;同时,它能支持高吞吐量,适合大规模数据集应用。这一目标可以看做是HDFS的架构目标。显然,这样的架构设计主要还是满足系统的质量属性,包括如何保证分布式存储的可靠性,如何很好地支持硬件的水平扩展,如何支持对大数据处理的高性能以及客户端请求的高吞吐量。所以,HDFS的架构设计颇有参考价值,在Hadoop的Apache官方网站上也给出了HDFS的架构指南。在The Architecture of Open Source Applications卷I的第8章也详细介绍了HDFS的架构。
HDFS(Hadoop Distributed File System)作为Hadoop下的一个子项目,是目前使用极为广泛的分布式文件系统。它的设计目的是提供一个高容错,且能部署在廉价硬件的分布式系统;同时,它能支持高吞吐量,适合大规模数据集应用。这一目标可以看做是HDFS的架构目标。显然,这样的架构设计主要还是满足系统的质量属性,包括如何保证分布式存储的可靠性,如何很好地支持硬件的水平扩展,如何支持对大数据处理的高性能以及客户端请求的高吞吐量。所以,HDFS的架构设计颇有参考价值,在Hadoop的Apache官方网站上也给出了HDFS的架构指南。在The Architecture of Open Source Applications卷I的第8章也详细介绍了HDFS的架构。
HDFS的高层设计看起来很简单,主要包含NameNode与DataNode,它们之间的通信,包括客户端与HDFS NameNode服务器的通信则基于TCP/IP。客户端通过一个可配置的TCP端口连接到NameNode,通过ClientProtocol协议与NameNode交互。而DataNode使用DatanodeProtocol协议与NameNode交互。一个远程过程调用(RPC)模型被抽象出来封装ClientProtocol和Datanodeprotocol协议。
通常,一个HDFS Cluter由一个NameNode和多个DataNode组成,且在大多数情况下,会由一台专门的机器运行NameNode实例。下图是HDFS的High Level Architecture:
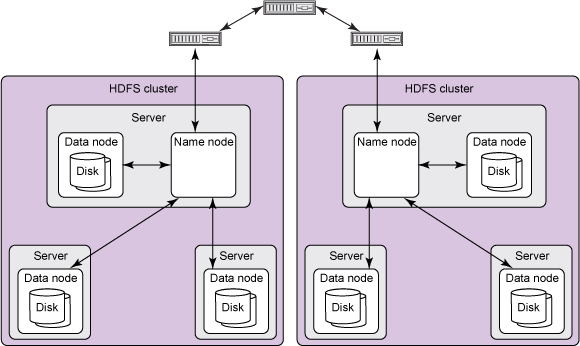
注意,在这个架构图中,观察各节点之间的通信,容易造成一个误解是NameNode会直接与DataNode通信。实则不然。虽然,NameNode可以看做是DataNode的管理者甚至是仲裁者,但由于DataNode的数量通常很多,且都是分布式部署在不同的机器上,若NameNode需要主动发起对各个DataNode的请求,会导致NameNode的负载过大,且对于网络的要求也极高。因此,在设计上,NameNode不会主动发起RPC,而是响应来自客户端或Datanode的RPC请求。如果NameNode需要获得指定DataNode的信息,则是通过DataNode调用函数后的一个简单返回值。每个DataNode都会维护一个开放的Socket,以支持客户端代码或其他DataNode的读写请求。NameNode知道该Socket的Host与Port。
 一个好的架构必然遵循了好的架构原则。HDFS架构有许多值得我们借鉴或参考的设计决策,其中它所遵循的架构原则,对HDFS满足架构目标起到了决定性的作用。这些原则包括:元数据与数据分离;主/从架构;一次写入多次读取;移动计算比移动数据更划算。
一个好的架构必然遵循了好的架构原则。HDFS架构有许多值得我们借鉴或参考的设计决策,其中它所遵循的架构原则,对HDFS满足架构目标起到了决定性的作用。这些原则包括:元数据与数据分离;主/从架构;一次写入多次读取;移动计算比移动数据更划算。
元数据与数据分离
这主要体现在NameNode与DataNode之分,这种分离是HDFS最关键的架构决策。这两种节点的分离,意味着关注点的分离。对于一个文件系统而言,文件本身的属性(即元数据)与文件所持有的数据属于两个不同的关注点。一个简单的例子是文件名的更改。如果不实现分离,针对一个属性的修改,就可能需要对数据块进行操作,这是不合理的。如果不分离这两种节点,也不利于文件系统的分布式部署,因为我们很难找到一个主入口点。显然,这一原则是与后面提到的主/从架构是一脉相承的。
NameNode负责维护文件系统的名字空间,任何对文件系统名字空间或属性的修改都将被NameNode记录下来。NameNode会负责执行与文件系统命名空间的操作,包括打开、关闭、重命名文件或目录。它同时还要负责决定数据块到DataNode的映射。从某种意义上讲,NameNode是所有HDFS元数据的仲裁者和资源库。
DataNode则负责响应文件系统客户端发出的读写请求,同时还将在NameNode的指导下负责执行数据库的创建、删除以及复制。
因为所有的用户数据都存放在DataNode中,而不会流过NameNode,就使得NameNode的负载变小,且更有利于为NameNode建立副本。
主/从架构
主从架构表现的是Component之间的关系,即由主组件控制从组件。在HDFS中,一个HDFS集群是由一个NameNode和一定数目的DataNode组成。NameNode是一个中心服务器,负责管理文件系统的名字空间(namespace)以及客户端对文件的访问。集群中的DataNode一般是一个节点一个,负责管理它所在节点上的存储。
一次写入多次读写
一次写入多次读写,即Write Once Read Many,是HDFS针对文件访问采取的访问模型。HDFS中的文件只能写一次,且在任何时间只能有一个Writer。当文件被创建,接着写入数据,最后,一旦文件被关闭,就不能再修改。这种模型可以有效地保证数据一致性,且避免了复杂的并发同步处理,很好地支持了对数据访问的高吞吐量。
移动计算比移动数据更划算
移动计算比移动数据更划算,即moving computation is cheaper than moving data。对于数据运算而言,越靠近数据,执行运算的性能就越好,尤其是当数据量非常大的时候,更是如此。由于分布式文件系统的数据并不一定存储在一台机器上,就使得运算的数据常常与执行运算的位置不相同。如果直接去远程访问数据,可能需要发起多次网络请求,且传输数据的成本也相当客观。因此最好的方式是保证数据与运算离得最近。这就带来两种不同的策略。一种是移动数据,另一种是移动运算。显然,移动数据,尤其是大数据的成本非常之高。要让网络的消耗最低,并提高系统的吞吐量,最佳方式是将运算的执行移到离它要处理的数据更近的地方,而不是移动数据。
HDFS在改善吞吐量与数据访问性能上还做出了一个好的设计决策,就是数据块的Staging。当客户端创建文件时,并没有立即将其发送给NameNode,而是将文件数据存储到本地的临时文件中。这个操作是透明的,客户端不会觉察,也不必关心。文件的创建事实上是一个流数据的写,当临时文件累计的数据量超过一个数据块大小时,客户端才会联系NameNode。NameNode将文件名插入文件系统的层次结构中,并且分配一个数据块给它。然后返回Datanode的标识符和目标数据块给客户端。接着,客户端将这块数据从本地临时文件上传到指定的Datanode上。当文件关闭时,在临时文件中剩余的没有上传的数据也会传输到指定的Datanode上。然后客户端告诉Namenode文件已经关闭。此时Namenode才将文件创建操作提交到HDFS的文件系统。这个操作的大致时序图如下所示:
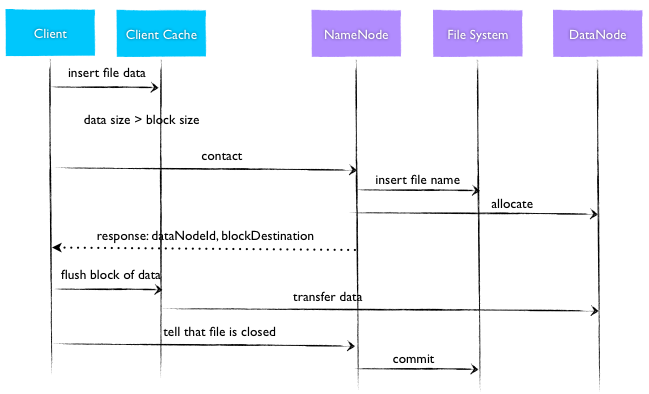
采用这种客户端缓存的方式,可以有效地减少网络请求,避免大数据的写入造成网络堵塞,进而提高网络吞吐量。