在我参与的一个项目中,遇见了一个结合功能性需求与非功能性需求,并要求同时满足的场景。它的功能其实很简单,就是需要向系统发出处理文件的请求。文件的处理则涉及到多个数据表的查询,对相关数据的解析,并依照事先设定好的模板填充数据,最后生成PDF文件。一旦文件处理完毕,就可以返回处理后的文件。由于该系统的业务特殊性,这一功能需求会在某个特定时间,迎来数以万计的客户请求。同时,文件处理功能是一个相对漫长的处理过程,且生成的文件较大。在系统的最初版本中,经历过数千人次的并发数,在只有一台服务器的情况下,导致了大量请求的阻塞。同时,由于加载文件和文件读写需要耗费内存,在请求较为频繁的情况下,多次抛出OutOfMemory异常。即使在最好的情况下,服务端响应了客户端请求,也可能花费大量的时间,严重影响了用户体验。
我们希望在后续版本中解决这一问题。然而,现实总是这么残酷。真正处理文件并提供下载功能的系统并不在我们的掌控之中。它是第三方Vendor提供的Web Service,我们开发的系统仅仅涉及到请求的转发,完成对该Web Service的调用;并在获得结果后,将响应(包含了文件流数据)返回给客户端。换言之,我们既不能改善文件处理的实现逻辑,以提高处理的速度;也无法对该Web Service进行水平伸缩,例如通过引入多台服务器建立集群和负载均衡的方式。
遭遇如此场景实属无奈,要得出好的设计决策就好似戴着镣铐跳舞,只有在自己的服务端下功夫。我们首先想到的是限流(throttle)的方式,通过引入一个类似Controller角色的对象RequestHandlerPool,对客户端的请求进行控制。我们可以设定一个阈值,一旦超过该阈值,就将后续的请求放入队列进行排队。这个限流可以采用简单地在内存实现请求池全局对象。当然,也可以考虑引入消息队列中间件。改进后的时序图如下所示:
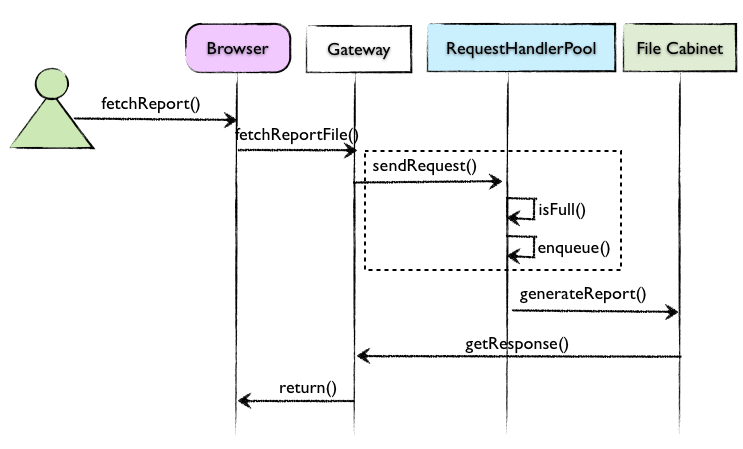
引入RequestHandlerPool仅仅是对请求进行了限制,从而避免请求过多导致File Cabinet的阻塞,或者导致抛出OutOfMemeory异常。但整体的处理时间并没有得到任何改善。我们首先考虑将该功能分为两阶段。第一阶段是发起对文件的处理请求,第二阶段则是下载处理好的文件。对于耗时较长的文件处理请求,可以考虑使用异步请求,一旦文件处理完毕,就可以通过Callback通知请求者。然而,由于文件处理的时间过长,可能会导致请求者不愿继续等待结果,从而退出系统,形成一次失败的请求。因而,我们考虑系统的Callback可以通过发送邮件的方式通知发出请求的客户,在邮件内容中附带下载地址,以供客户下载。
纵观整个场景,存在太多制肘,我们也没有太多好的解决方案。而且,我们还应该保证这个解决方案足够简单,因为我们需要在尽量短的周期内对原有方案进行改善,以迎接新一期的业务高峰。这些限制不同于架构约束,它常常迫使我们在逼仄的空间中闪转腾挪。我们还必须尽快地实现方案的原型,并营造与真实业务场景相当的数据,对其进行压力测试和性能测试。