我们有一个需求,需要在Scala中调用JDBC对数据库进行查询。然后将查询的结果ResultSet放到一个自定义结果类SqlResult中:
|
SqlResult的第一个构造函数参数存储的是数据表的列名,第二个参数存储数据表的行记录。由于ResultSet是Java中的一个对象,并不支持Scala的常用集合操作,因此这种转换是有必要的。我引入了隐式类(放在一个package object中)来完成这个转换,在转换过程中,由于需要对ResultSet进行遍历,因而引入了一个结果集List。默认情况下,Scala的List是immutable的,因此将其声明为var:
|
有了这个隐式转换,操作ResultSet就变简单了:
|
由于在前面的实现中,我初始化了一个Immutable的List,因此只能使用::添加每行从ResultSet得到的记录,然后再赋值给valueList。::方法只能将后加入的元素放到List的头部。所以在遍历完毕后,还需要做一个reverse操作。
我的感觉告诉我,这种先添加再反转的做法有些怪异。既然这里是以var的方式来使用Immutable List,为何不直接使用Mutable的集合呢?于是,我将前面的rows方法修改为:
|
因为rows方法返回的是Immutable List,所以在后面需要调用一个转换方法,将ListBuffer转换为List;但这个实现减少了对reverse方法的调用。于是,我产生了一个疑惑:这两种实现,究竟谁的性能更好呢?
为了判断彼此的性能,我首先写了一段简单的小代码,并放到perf.scala文件中:
|
为避免前后干扰,我选择以分支的方式通过传入参数分别执行。编译perf.scala文件。运行scala PerformanceTest 100000 list。此时运行结果为:
|
运行scala PerformanceTest 100000 listbuffer。运行结果为:
|
增加到200,000,结果迥然不同:
|
增加到500,000,结果迥然不同:
|
增加到1,000,000,结果就更明显了:
|
我们假定List方式为A,ListBuffer方式为B。整体看来,方式A消耗的时间都要小于方式B。当数据量越来越大时,这种差距就更加明显。问题在哪里?让我们来看看List与ListBuffer的实现。
首先,考察List对::以及reverse的实现:
|
::方法中的scala.collection.immutable.::实际上是一个继承自List的样例类。显然,这里的添加操作就相当于对List对象的创建。每次::操作的时间复杂度为O(C1)。此时的常量值C1基本等于1。由于每次遍历都要执行,因此总的时间为O(C1)*n。事实上,List数据结构增加一个头元素本身就非常简单,基本不耗时。但reverse操作要稍微复杂一些。它同样是复制了一个List,但对原List进行了遍历,然后将原有List的头元素与空List进行::操作,使其变成了last元素,如此遍历。因而时间复杂度为O(n)。
再来考察ListBuffer对+=以及toList的实现:
|
toList方法非常简单,因为ListBuffer内部存储了一个List对象,即这里看到的start。start会在每次添加元素时发生变化。因此看起来是一个转换方法,实则就是返回一个字段。时间复杂度为O(1)。再来看+=操作。首先,该方法会判断exported的值。如果为true,则需要执行copy方法。但是,根据OderSky对+=方法的描述(原书513页),只有在将ListBuffer转换为List之后,如果还要对原ListBuffer执行+=操作,才会执行copy方法:
However, the implementation of ListBuffer is such that copying is neces- sary only for list buffers that are further extended after they have been turned into lists. This case is quite rare in practice. Most use cases of list buffers add elements incrementally and then do one toList operation at the end. In such cases, no copying is necessary.
根据前面列出的toList方法,也可以看到:只要ListBuffer不为空,exported在执行了toList方法后,才会被设置为true。因此,在我们这个例子里,copy方法是不会执行的。显然,+=方法的执行耗时还是体现在if分支上。注意,这里的start类型为List[A]类型,且被声明为var;last0类型为::,同样被声明为var。在上面的语句中,将last0赋值给start,以及将last0赋值给val对象last1,是关键。此时,只要对last1的tl(即tail,声明为var的scala包下可访问的构造函数参数)进行赋值,实则就是会为start增加尾部元素。所以增加一个新元素,其时间复杂度应该为O(C2),并且这个C2一定大于1。针对我们的例子,每次遍历都要执行+=方法,因此总的时间复杂度为O(C2)*n。
这个推断是比较符合事实的。Odersky的著作Programming in Scala的第24章列出了各种集合的时间复杂度:
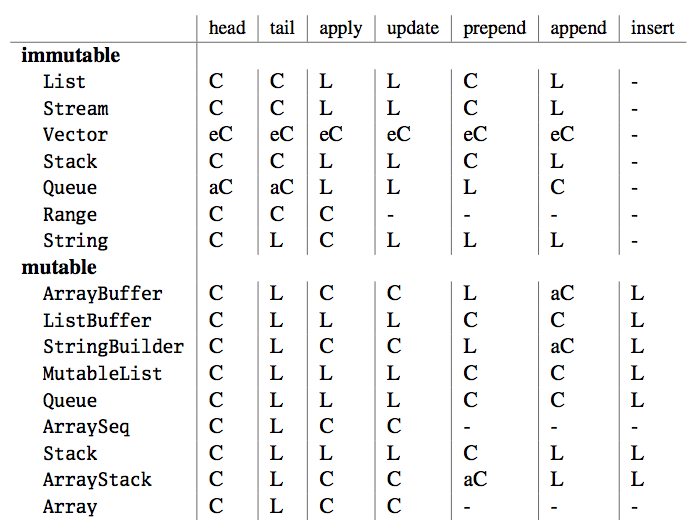
比较方案A的O((C+1)n),要判断谁更优,就是要看各自的C值是多大。分析实现,显然C2 > C1。此外,我们还不要忽略内存的消耗。仔细观察ListBuffer的实现,主要通过var变量start、last0以及一个临时的val变量last0,完成+=操作。相比较List而言,消耗的内存要大得多。事实上,在我将JVM的最大内存设置为512M的前提下,当数值为10,000,000时,执行方式A,消耗时间为119ms,而执行方式B时,就已经抛出OutOfMemoryError的异常了。
显然,当数据量比较大,且性能敏感时,在本文提到的场景下,应优先考虑使用List结合reverse的方式。当然,请注意,这里我虽然使用了Immutable的List,但我将其声明为了var变量。这可以避免在遍历过程中生成临时的List对象。如果采用纯函数无副作用的foldLeft进行转换,例如:
|
则其性能比较方式A有非常大的区别,数据量为1,000,000时,达到了845ms。而且在同等环境下,数据量达到5,000,000时,就已经抛出OutOfMemoryError的异常了。
看来,在Scala中操作集合并非易事。尤其是需要考虑性能和内存消耗时,更需要小心谨慎。事实上,我同时还比较了ArrayBuffer以及Vector在这种场景下的性能,都远不如这里列出的A方式。而采用foldLeft方式带来的问题更是我之前没有想到的。一定有优化的空间,也一定有更好的最佳实践。必须注意的是,本文主要比较的是添加元素的操作,且A方式的添加为preappend,B方式则为append。对于不同的集合,也有自身的适用场景。希望将来有时间整理一下这些集合操作在性能上的表现,从而选择合理的集合以及操作方式。