鉴于Farbox有更好的易用性,更新博客变得更方便。因而决定将github上的博客迁移到Farbox上。
新博客的地址为:http://zhangyi.farbox.com
鉴于Farbox有更好的易用性,更新博客变得更方便。因而决定将github上的博客迁移到Farbox上。
新博客的地址为:http://zhangyi.farbox.com

几天前,ThoughtWorks China咨询师团队召开了一次团结的大会,成功的大会。为期三天的会议,分享的内容并不亚于坊间举行的技术大会,包含了敏捷组织转型、C++重构、敏捷测试体系、持续交付整体解决方案、Spark执行模型、机器学习、Scala代码操练。课题五花八门,争辩激烈精彩。
临近尾声,洪敏提了一个好建议,让大家推荐自己平时用的高效率工具,于是就有了如下的一个清单。以下工具排名不分先后。
Pocket:一款超极好用的内容收藏工具,正如其名,像口袋一般方便。Pocket提供了各种形式的应用,包括Mac下的App、各种移动设备包括iphone、ipad、android、windows phone的APP以及网页版。同时它为firefox、chrome、safari、Opera提供了插件。当我们在浏览网页时,若发现内容精彩需要收藏,只需点击插件上的按钮,即可收藏,并能将收藏的内容同步到不同平台下的pocket中。我通常使用Pocket来收藏内容,而用EverNote来记录笔记,各有分工。
Spectacle:这并非Google眼镜,而是一个超炫的Geek工具,因为它帮我们定义(或者自定义)了诸多快捷键,使得我们无需使用鼠标,即可非常方便地移动窗口,改变窗口大小。
Skitch:来自EverNote,正如宣传所言“一圈一点”。在电脑、平板和手机上随时使用Skitch,轻松表情达意。堪称制作幻灯片神器啊。制作的图片还可以同步到EverNote中。
AutoJump:自动补完不算什么,一键直达目录才是终极神器。autojump是一个命令行工具,通过执行autojump [target directory],就可以直接到达你想要去的目录。
Any.Do:非常简单方便的todo list工具,可以帮助你快速地安排好今天、明天、将来想要做的事情。它的使用极为简单,只需手指轻轻一划,即可添加或删除待办项,非常符合我们操作手机的习惯。
Anki:要记住一些事情是需要方法的,同时还得善于利用时间。Anki通过创建flash card,然后自己编辑卡片的前后两面。前面为问题,后面为答案。一旦创建了卡片,随时就可以拿出来默记背诵。Anki支持Windows、Mac、Linux、iphone和Android等平台。利用Anki学习英语应该很不错,当然最重要的还在于持之以恒。
VisualGDB:一款用于开发和调试的IDE,集成了GCC和GDB,并可以将Remote Machine当做后端。可用于嵌入式和Android开发。
GoodReader:iPhone和iPad下的一款阅读软件,支持Office文档、PDF、TXT、HTML等文件浏览,支持视频、音频的播放(iPhone支持的媒体格式),支持横屏,还可以通过WIFI与PC或MAC共享文件!GoodReader是收费软件,不过如果我们经常使用iPad阅读PDF文件,就非常值得购买该工具啦。
CLion:ThoughtWorks似乎一直比较钟爱JetBrains开发的IDE,例如针对JVM开发的IntelliJ Idea,Ruby的RubyMine,Python的PyCharm,JavaScript的WebStorm。针对C和C++,之前JetBrains有AppCode,但它是基于Mac开发的。现在,有了CLion这个更好地支持跨平台的C/C++开发工具。
FarBox:一个绝对轻量级的博客托管服务平台,因为它可以集成DropBox,操作博客如在本地创建文件一般简单。结合Markdown,可以更好地发挥威力。当然,如果是托管到GitHub上,则推荐使用Octorpress。
youtube-dl:还在为不能方便地下载youtube视频而烦恼吗?可以试试youtube-dl命令行工具,可以通过homebrew安装。安装后,可以直接输入youbube-dl
Chrome vi:这是一款针对Chrome的插件,它使得你可以像操作vi那样操作Chrome。这样,在Chrome网页下就不需要操作鼠标去定位了,只需按下f键,chrome vi插件就会为网页上所有可定位的位置提供快捷键提示,然后通过敲击键盘对应的快捷键,就可快捷地将光标定位到对应位置进行操作。
clang-format:代码格式化工具。
cheat:linux命令小抄,比help和man命令更容易理解。cheat会告诉你一个命令如何使用,它没有提供其他额外多余的信息,只通过使用实例告诉你一个命令如何使用。
Alfred:这个不用讲了吧,用Mac的人如果不用Alfred,只能说out了。而且通过Alfred还可以定制workflow,这样可以更好地发挥Alfred的强大功能。
嗯,还有很多可以提高工作效率的工具。合理地使用这些工具,就可以留出更多的时间去学习、思考。这或许正是高效人士的秘诀。
 图片选自俄罗斯画家、美术理论家瓦西里·康定斯基作品。
图片选自俄罗斯画家、美术理论家瓦西里·康定斯基作品。
Steve Yegge在他特立独行的作品《程序员的呐喊》中写道:“我坚信代码最大的敌人就是体格”。不过他过于自大了,以为这只是像他那样牛逼的程序员才拥有的少数派观点;又或者说他过于悲观,以为程序员的世界还在拼代码的肌肉男臆想中。殊不知只要是曾经挣扎在庞大代码库泥潭中的程序员,就不会盲目崇拜代码的大块头。
可惜,“知行合一”非圣人不可以做到,梦想的光芒常常难以照进现实的阴影。要缩小代码的体格,似乎比减肥还要艰难。软件系统像一条贪吃蛇,吃掉一切功能,最后越变越长,在局限的空间里再也无法做到从容的转折腾挪,最后活活困死。偏偏还有人以能掌控千万级代码的软件系统为荣。——“兄弟不才,做过一系统,代码达到了两千万行,真是一场噩梦啊!”,程序君一边摇头作痛苦状,嘘声叹气,但察其眼角眉间,藏不住的却是得意和炫耀。
因而,我们一边在愤慨代码日益膨胀的体格,一边又在做着堆代码的增肥工作。软件从来都不是一个人写完的,需求也从来不会稳定不变,于是乎出现了超过数个屏幕的分支语句,出现了大量注释过的代码残骸,于是乎有了拷贝粘贴,程序员渐渐开始降低坏代码的容忍度,开始得过且过。
面对日益膨胀的代码体格,Steve的呐喊是换语言,因为他是Ruby粉和Python粉的缘故,恨不得把所有系统都换成Ruby或者Python,要么就是Lisp。作为Scala粉的我,当然也恨不得所有Java项目都换成Scala。让我再写啰嗦的Java代码,真是痛不欲生,生不如死啊。支持了lambda的Java 8也许还能挽救我,但我还是钟情Scala。
太天真了!首先是换不了,其次是换了也没用。你真以为换语言如换刀,宝刀在手,就能割去那些臃肿的代码,还代码一个苗条身材?——你以为是抽脂啊!Ruby也可以写出烂代码,Java也能写出漂亮的程序,关键不在于语言。正如武林高手比武并不在于刀剑的利钝,要分出武功高低,根本还是功力和招式。只有同等高手之间的厮杀,手握一柄利器才能成为制胜法宝。
代码的臃肿关键还在于分解与去重。Unix大吗?大,而且必须大。但它又很小,因为它以内核形式确立了系统的边界,同时遵循KISS原则,将大功能分解为小程序,每个小程序只能完成一个功能,任何复杂的操作都必须分解成一些基本步骤,由这些小程序逐一完成,再组合起来得到最终结果。分解的一个难题是如何定边界,换言之就是如何做到“高内聚、松耦合”。另一个难题在于组合,即该如何把这些分解的细小功能再糅合起来,形成一个整体。这也是为何Micro Service被鼓吹了多少遍,仍然有人保持观望态度的原因。
若说掌握分解这门技艺的高手中高手,还得数庖丁这哥们,“彼节者有闲,而刀刃者无厚,以无厚入有闲,恢恢乎其于游刃必有余地矣,是以十九年而刀刃若新发于硎。”眼睛都修炼成了X光,能够透过牛皮看清骨肉经络,以至于能够无厚入有闲,像舞蹈一般变屠牛为行为艺术,举手投足间,潇潇洒洒地把牛给宰了,还挥挥衣袖,不带走一点血。对软件系统的分解,我们能做到像庖丁那般识破依赖,判断“有闲”之节者,进而做到合理解耦吗?
去重的根本其实还是分解,粒度可以是函数、类、模块、子系统。程序员需要有洁癖,重复就是最大的dirty,可惜打扫卫生需要付出。写代码是件劳心劳力的事儿,总会有人偷懒的。Deadline又是一把悬在程序员头上的达摩克利斯之剑,在急迫的催促声中,程序员寻找到了心里安慰,因为时间是允许降低质量的最完美借口。——当然,时间也是最残忍的。程序员干的是刀口舔血的生活,出来混,迟早是要还的。程序世界,就是佛家所谓的“因果世界”啊。
去重的关键并不在于技巧(程序员都不是傻子,只要愿意学,什么技巧不能学会?),而在于勇气和决心。重复是敌人,而且是大块头的敌人,它就这般随意地站着,勾起小指头,傲慢地挑衅着你。而你,却未必有战风车的勇气。是明知必败吗?还是不可战胜?未战先怯,这场战争你已经败了。我见到的诸多遗留系统,重复代码都是这样开始蔓延的。——时间,见鬼的时间,其实大多数时候它都是你举白旗时找来贴脸的遮羞布。
我常常说程序员要懒,例如要把重复的过程变成自动化,例如不要重复制造轮子,例如竭力少写代码完成更多的事。可惜,我们多数时候把这种懒,用错了地方。懒于打扫,懒于行动,却又不计后果的吃,代码的体格怎么能够减得下来?就看着代码的体格一天天膨胀下去,然后呜呼哀哉吧。
对于一个具有相当技术门槛与复杂度的平台,Spark从诞生到正式版本的成熟,经历的时间如此之短,让人感到惊诧。2009年,Spark诞生于伯克利大学AMPLab,最开初属于伯克利大学的研究性项目。它于2010年正式开源,并于2013年成为了Apache基金项目,并于2014年成为Apache基金的顶级项目,整个过程不到五年时间。
由于Spark出自伯克利大学,使其在整个发展过程中都烙上了学术研究的标记,对于一个在数据科学领域的平台而言,这也是题中应有之义,它甚至决定了Spark的发展动力。Spark的核心RDD(resilient distributed datasets),以及流处理,SQL智能分析,机器学习等功能,都脱胎于学术研究论文,如下所示:
Discretized Streams: Fault-Tolerant Streaming Computation at Scale. Matei Zaharia, Tathagata Das, Haoyuan Li, Timothy Hunter, Scott Shenker, Ion Stoica. SOSP 2013. November 2013.
Shark: SQL and Rich Analytics at Scale. Reynold Xin, Joshua Rosen, Matei Zaharia, Michael J. Franklin, Scott Shenker, Ion Stoica. SIGMOD 2013. June 2013.
Discretized Streams: An Efficient and Fault-Tolerant Model for Stream Processing on Large Clusters. Matei Zaharia, Tathagata Das, Haoyuan Li, Scott Shenker, Ion Stoica. HotCloud 2012. June 2012.
Shark: Fast Data Analysis Using Coarse-grained Distributed Memory (demo). Cliff Engle, Antonio Lupher, Reynold Xin, Matei Zaharia, Haoyuan Li, Scott Shenker, Ion Stoica. SIGMOD 2012. May 2012. Best Demo Award.
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing. Matei Zaharia, Mosharaf Chowdhury, Tathagata Das, Ankur Dave, Justin Ma, Murphy McCauley, Michael J. Franklin, Scott Shenker, Ion Stoica. NSDI 2012. April 2012. Best Paper Award and Honorable Mention for Community Award.
Spark: Cluster Computing with Working Sets. Matei Zaharia, Mosharaf Chowdhury, Michael J. Franklin, Scott Shenker, Ion Stoica. HotCloud 2010. June 2010.
在大数据领域,只有深挖数据科学领域,走在学术前沿,才能在底层算法和模型方面走在前面,从而占据领先地位。Spark的这种学术基因,使得它从一开始就在大数据领域建立了一定优势。无论是性能,还是方案的统一性,对比传统的Hadoop,优势都非常明显。Spark提供的基于RDD的一体化解决方案,将MapReduce、Streaming、SQL、Machine Learning、Graph Processing等模型统一到一个平台下,并以一致的API公开,并提供相同的部署方案,使得Spark的工程应用领域变得更加广泛。

一艘货轮满载着货物从港口启航,向浩瀚的大海深处破水而去。海面平静,微微皱起波浪,从容而显得宽容。然而,货轮的步履却有些蹒跚,发动机“轰轰轰”地嘶吼着,不堪重负,却无法让船只游得更快,倒像是海水咬住了船底往下在拖曳。
“嘟——嘟——嘟”,突然警报声响起,甲板上变得喧闹起来,一个水手模样的年轻人声嘶力竭地呐喊:“船超重了,快快快……快卸货!”声音急迫,甚至能听到哭音。然后,又是一阵喧嚷,似乎是在争吵甚么,就看到一个胖胖的中年人冲了出来。看他那肥胖的体型,真难想到他的身手竟然如此敏捷,如海豹一般破开人群,两手挥舞,大声喊道:“怎么了?怎么了?”,他停下来,吼道:“我看哪个不长眼的家伙敢卸我的货!谁敢!”
船长走了过来,略带恭敬地对那中年人说道:“老板,你看,这船超载了,船身吃紧,已经发出超重警报了。倘若不减轻船的重量,这船开不了多久就得沉了啊!”
“他奶奶的,这船可真秀气啊!”中年人一边骂骂咧咧,却也知道形势紧迫,容不得自己不下决断。可是心里总存着侥幸心理,突然灵机一动,一把拉过船长,指着这艘货轮问道:“既然这船超重,那我问你,除了货物,这船上还有哪些东西占了船身的重量?”
船长一听,立刻明白老板心里的小九九,没好气地回道:“除了货物,占了这船重量的就还有人、淡水、食品,还有救生圈、救生衣、救生艇。老板你看那样不顺心,你就扔哪样吧!”
嘿,回到现实中来吧。回答问题:倘若你是老板,你会扔哪样呢?稍有理智的人,都不难做出正确的选择。——然而,为何在软件开发过程中,我却常常看到有人选择丢弃救生圈、救生衣、救生艇呢?哪怕它们的重量对于整艘船而言如同九牛一毛,却总有人存着侥幸,认为船就超了那么一点点,或许扔出几个救生圈,就能恢复重量到安全线;于是,货物得以幸存,可以避免不必要的损失了。
或许,我们没这么傻吧。那么,让我们想想。
假设将这航行比作是软件开发的过程,那么载货到达目的地,就是实现软件需求。只有交付了货物,才算是实现了价值。至于淡水、食品以及船只,就是开发的工具与环境,而救生圈、救生衣、救生艇,就是我们在开发过程中需要编写的自动化测试(单元测试、集成测试、验收测试等)。我们需要这些测试来随时检测开发功能是否有误,及时反馈,就像在航行过程中,若是有人溺水,可以用救生衣、救生圈挽回一条生命一般。
可一旦开发时间紧促,人手严重不足,进度压力山大时,我们想到了什么呢?对于我见过的多数软件团队而言,每当面临如此窘境时,首先想到的就是减少甚至不做自动化测试。有人认为自动化测试没有价值,浪费成本;有人认为自动化测试可以以后再补,先把功能完成再说;有人认为有了手动测试,就足以保障项目的质量……如此这般,自动化测试就这般被忽略了,沦落到随时可以抛弃的地位。
倘若软件开发就只有这一个阶段,没有需求变更,没有后续开发,没有软件维护。项目的代码库如树苗一般在阳光雨露下茁壮成长,没有大风狂吹,没有烈日暴晒,没有大雨倾盆,亦没有虫蚁啃啮,那自然由得它去。然而,现实世界哪有如此美好!
Michael Feather将没有自动化测试的代码称为“遗留代码”,温伯格在《咨询的奥秘》中则认为应该将“维护”工作视为“设计”工作。自动化测试是修改的基础,重构的保障,设计的规约,演化的文档。它的重要性怎么强调都不过分,然而很可惜,在很多软件项目开发中,它甚至不如“鸡肋”的地位,说放弃就放弃了,在决定当时,毫不觉得可惜。至于以后的以后,不远的未来,谁还顾得上!!?债欠下了,什么时候偿还呢?——不知道!到了催债的那天,再想办法还债吧。
鸵鸟心态害死人啊!
扪心自问,我们经历过维护的苦楚吗?体验过修改代码的烦恼吗?修复过不胜其扰的缺陷吗?答案若是肯定,那么,如果老天再给你一次机会,把选择自动化测试的权利放在你面前,作为“曾经沧海难为水”的你,你会怎么选?——所以,我想问问程序员们:今天,你写自动化测试了吗?
后记:其实我很想写:程序员要是写代码不写测试,就是耍流氓,就是做爱不带套。可我纯洁啊,没好意思写出来。可总觉得这么经典的语录藏在我心里,小心憋不住。把心一横,他奶奶的,毕竟话糙理不糙啊!这不,一激动,还是吐露真言了。终归脸皮薄,没好意思写进正文,就这般猥琐地躲在文章后面,算是偷窥,觑觑究竟有谁真有耐心读到文章末尾,听听我的真心大实话。

古希腊哲学家巴门尼德认为:“人的思想和言语都有一个载体,如果你在这一时间和另外一个时间想到或者谈到同样一件东西,那就说明这件东西在这段时间内没有变化,如有变化的话,你说的就不是同一件东西。”
这让我想起对象的实例。在面向对象设计中,默认情况下并没有约束类的实例是否为可变,这意味着我们可以通过某种方式改变实例的状态。这体现了实例的可变特征。然而,若是站在内存的角度观察实例,则又不然。无论它在内存中存储的状态如何变化,该实例的对象标识依旧是保持不变的。显然,变与不变是相对的。
切换到DDD的命题中,所谓“实体”就是那种具有唯一的可识别可跟踪ID的对象。这个ID并非程序语言在内存中为它分配的对象标识,而是从领域角度来看,由设计者为其识别,由创建者为其分配,因而具有领域语义。实体的状态当然是可变的,然而实体ID在这个实体的生命周期中却是不可变的。
与之相对的是值对象。在DDD中,强调将领域对象严格区分为实体和值对象。一个指导原则是,当你无法分辨某个领域对象究竟是实体还是值对象时,应优先将其建模为值对象。这有助于我们更好地利用值对象的不可变性。
不可变的对象能够更好地维护,因为你不用操心它的值变化,也无需追踪变化的轨迹。不变性天生支持并发。这就衍生出面向对象设计中的Immutable模式。例如Java和C#中的String类型,皆为Immutable模式的实现。
可若放在函数式编程中,这种模式就显得有些可笑了。尤其在纯函数式编程的世界里,任何东西都应该是不变的。
这种不变意味着只要它存在,就不可修改,而且恒古不变。这种追究变化背后的不变性,一直是古希腊哲学乃至科学的基本原则。物质是否永恒不变,在哲学中一直是引人深思的命题或假设;但在函数式编程中,它几乎被证明了。例如,在Haskell中,对List的任何操作,即使调用++对List进行合并,返回的都是全新的List对象,原有对象不会有任何变化。
罗素在《西方哲学简史》中写道: 有的神秘主义者认为永恒并不是指时间上的永久,它是独立于时间之外的,无前无后、无因无果,也没有逻辑可循。
我觉得函数式编程追求的不变性,可以划入这个范畴。
赫拉克利特说:“人不能两次踏进同一条河流”。这是赫拉克利特终极的哲学观,即万物随时在变。软件系统就是这样一条河流,它无时无刻不在变化,正如水不断的流动,需求也总是在变化。但若抛开原子裂变、放射衰变的科学原理,我们似乎也可以将组成整条河流的每一滴水,看做是不变的基本组成要素。这个要素就是Monad中的Identity(幺元或单位元)。这个Identity表达了单一、恒等的概念,例如Int类型中加减法运算半群(SemiGroup)中的Zero,就是一个Identity,因为半群中的任何元素a与Zero结合,依然是元素a本身。
水是如何组成一条河流的呢?这取决于组合子(Combinator)的设计与组合。只要我们找到万物的基本要素,继而设计出各种组合子,就可以演绎出世间不同的物。例如水滴虽可以组合为河流,却也可以组合为橙汁,只要我们加入橙子的另一个组合子即可。这就是面向组合子(Combinator Oriented)的设计思想。显然,它与面向对象的设计哲学背道而驰。
以哲学史观之,函数式思想更符合古典的朴素哲学观。在古希腊哲学家中,泰勒斯认为世界的元素为水,阿那克西美尼认为世界的元素是气,赫拉克利特认为世界的元素是火,而恩培多克勒则糅合了这些思想,认为世界的元素有土、气、火、水四种。而观中国古代哲学,则有五行学说认为宇宙万物都由金木水火土五种基本特性的运行和变化所构成。
不论构成万物的基本元素为何,这种哲学观不正是函数式编程的设计观吗?
这两日,我参加了Implementing Domain Driven Disign一书作者Vaughn Vernon组织的IDDD Workshop。培训中,Vernon带领我们针对Domain Event进行了一次建模工作坊。

在领域驱动设计中,Domain Event变得越来越重要。在Implementing Domain Driven Disign这本书中,Vaughn Vernon甚至将Domain Event上升到了一等公民的地位。
那么,Domain Event到底是什么?Domain Event即领域事件,是指领域中发生的事实(facts)。当满足某个条件时,某个发起者就会触发事件产生。因而在对事件建模时,我们可以关注统一语言中如下的关键词汇: “当…” “如果发生…” “当…的时候,请通知我” “发生…时”
“事件为事实(fact)”这一描述让我对“事件”本身有了更准确的认识。它让我想起两篇发表在InfoQ上的文章。一篇文章为《Datomic的架构》。文中提到:“信息是一组事实(facts),事实是指一些已经发生的事情。鉴于任何人都无法改变过去,这也意味着数据库将累积这些事实,而非原地进行更新。虽然过去可以遗忘,但却是不能改变的。”同理推之,若事件即事实,那么它也是不可改变的。对于这些历史发生的“事实”,我们需要“立此存照”——于是,这就引出了Event Store或者Event Sourcing。我会在后续的文章深入分析Event Store与Event Sourcing。
另一篇文章是徐昊的《运用四色建模法进行领域分析》。文中表达了类似的思想:“任何的业务事件都会以某种数据的形式留下足迹。我们对于事件的追溯可以通过对数据的追溯来完成。……你无法回到从前去看看到底发生了什么,但是却可以在单据的基础上,一定程度的还原当时事情发生的场景。当我们把这些数据的足迹按照时间顺序排列起来,我们几乎可以清晰的推测出这个在过往的一段时间内到底发生了那些事情。”
在四色建模分析法中,徐昊认为应该将“时标性对象(moment-interval)”作为建模的起点。我在这里并不是要介绍四色建模法,这个话题留待以后再讲。我试图阐释的观点在于,如果事件与时间相关,那么在对事件进行建模时,就可以针对业务场景确定一条时间线,并通过分析业务状态的各种变迁,得到我们希望获得的事件模型。这正是这个工作坊的切入点。
整个事件建模的活动可以分为四个步骤:
1. 选定某个自己熟悉的领域,然后针对时间线去寻找那些用过去时态表现的事件;找到这些事件后,用黄色即时贴写出事件名称,形式如:OrderFilled。
2. 针对每个事件,对触发事件的Command对象进行建模,并用绿色即时贴写出Command的名称。对Command对象进行建模并非单纯地为了寻找Command对象,而是为了更深一步地验证之前建模的事件模型。在思考触发事件的对象时,我们可能会发现一些遗漏又或者多余的事件。
3. 判断这些事件应该属于哪个聚合对象,找到它们,然后写在紫色即时贴上。
4. 对这些识别出来的Event、Command、Aggregate进行分类,判断它们到底属于哪个Bounded Context,并用红色即时贴标出。

这种Workshop不仅只针对培训,它更应该运用到团队进行领域驱动设计的过程中。这也正是我一直在提倡的所谓“可视化设计”。可视化设计并非一个噱头,更不是为了美观好看,而是希望以直观简单的形式展现设计思路,尤其需要让整个团队成员都能以协作互动的形式参与到这个设计过程中。群策群力,头脑风暴,如此方能获得更好的设计方案,并以这种团队行为的方式完成知识的共享与传递。其实,“架构”究竟是什么,不就是一种软件设计的知识吗?设计架构,重要在于交流,在于知识传递,而不仅仅是严谨完整的解决方案文档。
我无可救药地成为了Scala的超级粉丝。在我使用Scala开发项目以及编写框架后,它就仿佛凝聚成为一个巨大的黑洞,吸引力使我不得不飞向它,以至于开始背离Java。固然Java 8为Java阵营增添了一丝亮色,却是望眼欲穿,千呼万唤始出来。而Scala程序员,却早就在享受lambda、高阶函数、trait、隐式转换等带来的福利了。
Java像是一头史前巨兽,它在OO的方向上几乎走到了极致,硬将它拉入FP阵营,确乎有些强人所难了。而Scala则不,因为它的诞生就是OO与FP的混血儿——完美的基因融合。
“Object-Oriented Meets Functional”,这是Scala语言官方网站上飘扬的旗帜。这也是Scala的野心,当然,也是Martin Odersky的雄心。
然而,一门语言并不能孤立地存在,必须提供依附的平台,以及围绕它建立的生态圈。不如此,语言则不足以壮大。Ruby很优秀,但如果没有Ruby On Rails的推动,也很难发展到今天这个地步。Scala同样如此。反过来,当我们在使用一门语言时,也要选择符合这门语言的技术栈,在整个生态圈中找到适合具体场景的框架或工具。
当然,我们在使用Scala进行软件开发时,亦可以寻求庞大的Java社区支持;可是,如果选择调用Java开发的库,就会牺牲掉Scala给我们带来的福利。幸运的是,在如今,多数情况你已不必如此。伴随着Scala语言逐渐形成的Scala社区,已经开始慢慢形成相对完整的Scala技术栈。无论是企业开发、自动化测试或者大数据领域,这些框架或工具已经非常完整地呈现了Scala开发的生态系统。
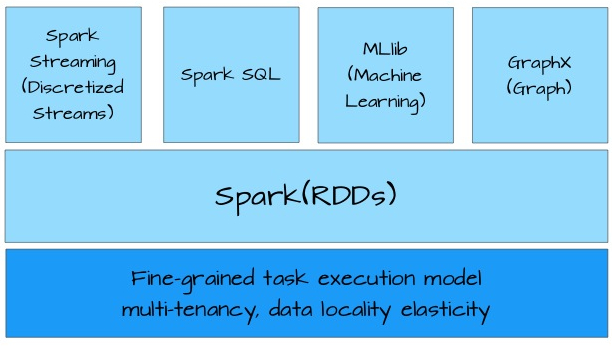 与许多专有的大数据处理平台不同,Spark建立在统一抽象的RDD之上,使得它可以以基本一致的方式应对不同的大数据处理场景,包括MapReduce,Streaming,SQL,Machine Learning以及Graph等。这即Matei Zaharia所谓的“设计一个通用的编程抽象(Unified Programming Abstraction)。这正是Spark这朵小火花让人着迷的地方。
与许多专有的大数据处理平台不同,Spark建立在统一抽象的RDD之上,使得它可以以基本一致的方式应对不同的大数据处理场景,包括MapReduce,Streaming,SQL,Machine Learning以及Graph等。这即Matei Zaharia所谓的“设计一个通用的编程抽象(Unified Programming Abstraction)。这正是Spark这朵小火花让人着迷的地方。
要理解Spark,就需得理解RDD。
RDD是什么?
RDD,全称为Resilient Distributed Datasets,是一个容错的、并行的数据结构,可以让用户显式地将数据存储到磁盘和内存中,并能控制数据的分区。同时,RDD还提供了一组丰富的操作来操作这些数据。在这些操作中,诸如map、flatMap、filter等转换操作实现了monad模式,很好地契合了Scala的集合操作。除此之外,RDD还提供了诸如join、groupBy、reduceByKey等更为方便的操作(注意,reduceByKey是action,而非transformation),以支持常见的数据运算。
 之所以选择可视化手段来进行软件设计——非UI或UX的设计——是基于我对设计的理解:设计并非文档,而是交流。那种依靠一位英雄来完成所有的设计,并编撰为详尽的文档,然后让程序员连蒙带猜按图索骥的设计方式,完全不可取。尤其在一个自组织的开发团队中,我们希望人人都是程序员,人人都是软件设计师,人人都是架构师。
之所以选择可视化手段来进行软件设计——非UI或UX的设计——是基于我对设计的理解:设计并非文档,而是交流。那种依靠一位英雄来完成所有的设计,并编撰为详尽的文档,然后让程序员连蒙带猜按图索骥的设计方式,完全不可取。尤其在一个自组织的开发团队中,我们希望人人都是程序员,人人都是软件设计师,人人都是架构师。
那么,该如何做到充分的交流,就像风吹过树林,不分彼此的摇动每一片树叶?我想到最简单直截的方式:可视化。然而,此可视化非UML之所谓的“一图胜千言”。没错,我们当然需要绘制设计图,而且必须绘制设计图,但我们更希望是以草图的形式,并辅以视觉引导,来推着团队的每个成员,渐进地完善设计,直到抵达设计的真相。我们没有门派偏见,亦不愿邯郸学步,因而我们既信奉“拿来主义”,又会依据设计的本质原则与真谛,进行了细微的创新。创新未必一定是无中生有,“旧瓶装新酒”或是对经典的追随,“新瓶装旧酒”又何尝不能看作是创意的包装!
此次在TID会议上的可视化设计工作坊算是我与姜志辉针对此主题的一次彩排吧。我们从未就此话题有过深度合作,但是,我们对设计的理解是志同道合的,说得肉麻点,有心有灵犀的感觉。下图是整个工作坊的路径缩影:
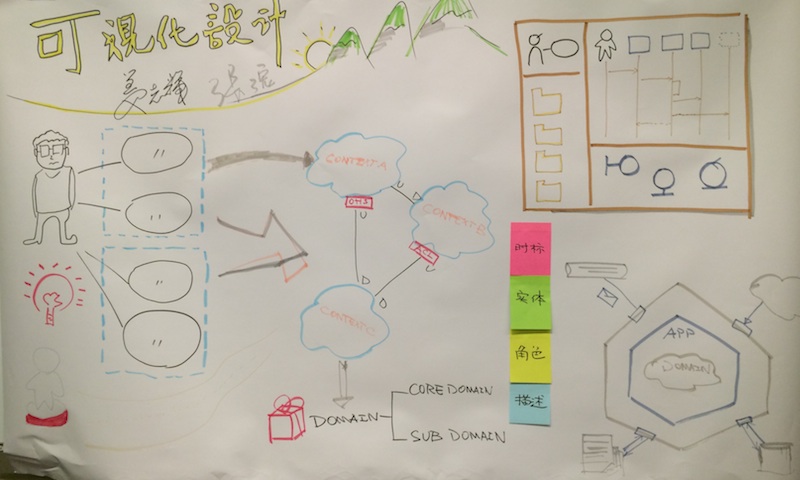
我们的主线就是设计的可视化,整个过程我们通过草图、即时贴、画布等多种方式来触发团队成员之间的交流与讨论。至于方法工具箱,则几乎等同于一个大杂烩了。我们使用经典的用例图进行需求分析(我们会以商业画布为需求的起点,因为时间关系省去了此步骤),继而根据用例的边界获得DDD中所谓的Bounded Context。
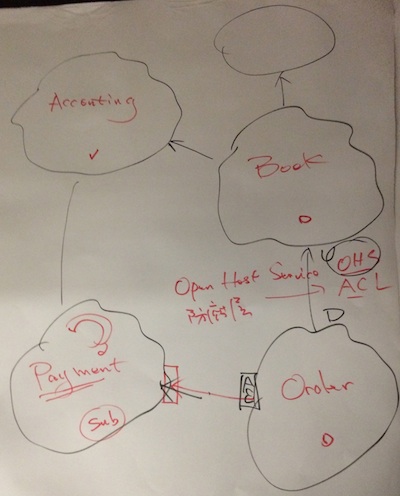
通过运用DDD的Context Map,我们辨别出Context之间的上下游关系与各种集成方式,继而利用Cockburn的六边形架构以及传统的分层架构,驱动出系统的应用逻辑架构与物理架构。
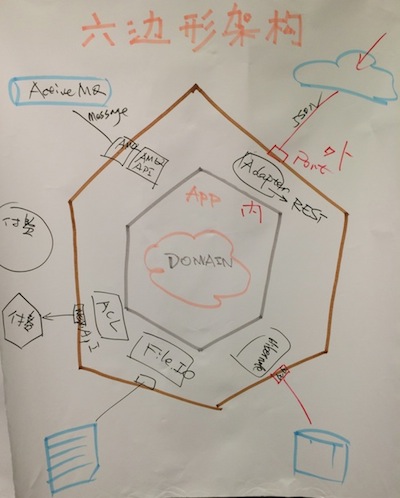
然后,我们跳入Context的内部,开始领域建模。我们尝试了两种领域建模方式:健壮性分析与四色建模,以此为起点,我们可以得到粗略的CRC草图,之后就进入了我和姜志辉提出的设计画布。

我们希望看到的是这样的交流场景,如此才可碰撞出好设计的火花。


可视化设计并非仅能针对一个新系统,或者仅用于设计阶段。
例如,我曾经在客户处通过运用我提出的依赖沉淀图,让团队成员以交流协作的方式完成对遗留系统模块依赖关系的梳理。这种依赖关系梳理虽然可以利用工具来生成,但采用可视化的方式却可以充分保障成员之间的知识共享。它追求的并非只是结果,而是整个协作的过程。又例如,我们也可以在Inception阶段,通过可视化设计来评估风险,或针对候选技术进行Spike,又或者运用六边形架构等方式来梳理系统与周边系统之间的关系,以便于团队理解整个软件产品的生态系统。
其实,这种可视化设计,我更倾向于称之为“体验式设计”,但它与ThoughtWorks提出的XD并非专注同一个层面的内容。当然,这种体验式的软件设计,我还处于试验的摸索阶段。