Spark具有先进的DAG执行引擎,支持cyclic data flow和内存计算。因此,它的运行速度,在内存中是Hadoop MapReduce的100倍,在磁盘中是10倍。如下是对比图:
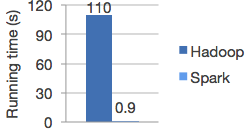
这样的性能指标,真的让人心动啊!
Spark的API更为简单,提供了80个High Level的操作,可以很好地支持并行应用。它的API支持Scala、Java和Python,并且可以支持交互式的运行Scala与Python。来看看Spark统计Word字数的程序:
file = spark.textFile("hdfs://...")
file.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
|
看看Hadoop的Word Count例子,简直弱爆了,爆表的节奏啊:
public class WordCount {
public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
}
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
|
当然,Hadoop有自己的一套框架,为整个的大数据处理做支持,例如HIVE,例如HDFS。Spark也不逊色,也有自己的SQL框架支持,即Shark,此外还支持流处理、机器学习以及图运算:
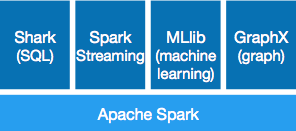
Spark并没有自己的分布式存储方案。不过已经有了强悍的HDFS,同为Aparch旗下的Spark又何必再造一个差不多的轮子呢?所以Spark可以很好地与Hadoop集成。例如可以运行在Hadoop 2的YARN集群下,可以读取现有的Hadoop数据。当然,Spark自身也支持standadlone的部署,或者部署到EC2等云平台下。除了可以读取HDFS数据,它还可以读取HBase,Cassandra等NoSQL数据库。这扩大了Spark的适用范围。
目前的Spark官方发布还仅仅是0.9的孵化版本,这为它的商用造成一点点阻碍。针对一个新的大数据项目而言,是选用Spark,还是Hadoop,还真的难以抉择。当然,对于我们这种玩技术的,从来都是喜新厌旧,心里自然是偏向Spark了。